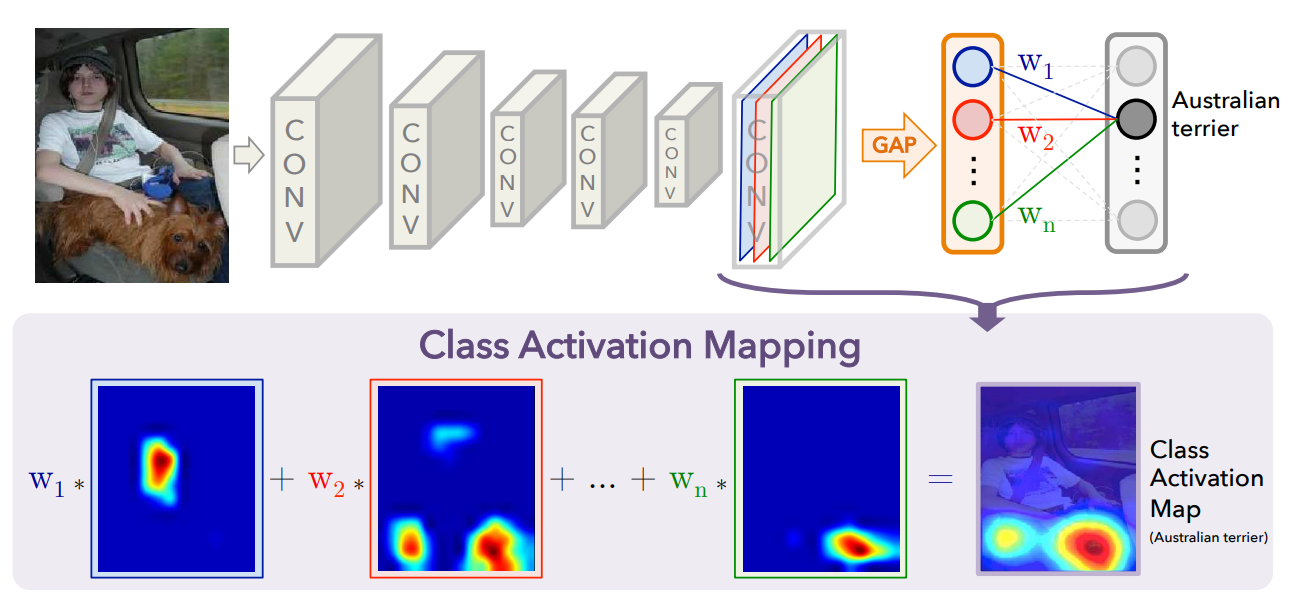
基于概念的解释方法是18年提出的新方法,其动机在于先前的方法仅使用图像的像素级特征,其通常稀疏且不易被人类理解。这是因为人类观察图像时,通常看到的是某个像素区域或图像中的某一部分,而非逐个像素的观察图像。由于其更优秀的解释表现,该方法也有更多的关注。本文将这一方法从提出到目前的研究现状(to my best knowledge)进行梳理。
CAV
Concept activation vector( CAV,概念激活向量 )[1]是基于概念的解释方法的开山之作,其框架如图1.1所示。每个概念由一个输入图像的集合定义。例如,要定义“卷发”这一概念,用户需要使用若干包含弯卷头发的发型的相关图像。
设x ∈ R n x \in \mathbb{R}^{n} x ∈ R n l l l m m m f l : R n → R m f_{l}: \mathbb{R}^{n} \rightarrow \mathbb{R}^{m} f l : R n → R m
第一步,选取可以代表一个概念的图像集合,以定义一个概念。作者认为这一策略的优点是,概念的定义不会受限于图像中已经存在的特征、标签的相关信息或是只能使用已经被用于网络训练过程中的图像,给予其极大的灵活性。同时,这一图像收集过程可以由图像搜索引擎 代替人手工完成。
第二步,寻找第l l l l l l 。此时,将概念激活向量定义为在激活空间 。此时,将概念激活向量定义为在激活空间 。此时,将概念激活向量定义为在激活空间
第三步,使用方向导数定义概念的敏感度。令v C l ∈ R m \boldsymbol{v}_{C}^{l} \in \mathbb{R}^{m} v C l ∈ R m l l l C C C k k k S C , k , l ( x ) S_{C, k, l}(\boldsymbol{x}) S C , k , l ( x )
S C , k , l ( x ) = lim ϵ → 0 h l , k ( f l ( x ) + ϵ v C l ) − h l , k ( f l ( x ) ) ϵ = ∇ h l , k ( f l ( x ) ) ⋅ v C l (1.1) \begin{aligned}
S_{C, k, l}(\boldsymbol{x}) &=\lim _{\epsilon \rightarrow 0} \frac{h_{l, k}\left(f_{l}(\boldsymbol{x})+\epsilon \boldsymbol{v}_{C}^{l}\right)-h_{l, k}\left(f_{l}(\boldsymbol{x})\right)}{\epsilon} \\
&=\nabla h_{l, k}\left(f_{l}(\boldsymbol{x})\right) \cdot \boldsymbol{v}_{C}^{l}
\end{aligned} \tag{1.1}
S C , k , l ( x ) = ϵ → 0 lim ϵ h l , k ( f l ( x ) + ϵ v C l ) − h l , k ( f l ( x ) ) = ∇ h l , k ( f l ( x ) ) ⋅ v C l ( 1.1 )
其中h l , k : R m → R h_{l, k}: \mathbb{R}^{m} \rightarrow \mathbb{R} h l , k : R m → R S C , k , l ( x ) S_{C, k, l}(\boldsymbol{x}) S C , k , l ( x )
第四步,计算Testing with CAVs( TCAV )评估以整个类图像中概念的敏感度。对于类别k k k X k X_{k} X k
TCAVQ C , k , l = ∣ { x ∈ X k : S C , k , l ( x ) > 0 } ∣ ∣ X k ∣ (1.2) \operatorname{TCAVQ}_{C, k, l}=\frac{\left|\left\{\boldsymbol{x} \in X_{k}: S_{C, k, l}(\boldsymbol{x})>0\right\}\right|}{\left|X_{k}\right|} \tag{1.2}
TCAVQ C , k , l = ∣ X k ∣ ∣ { x ∈ X k : S C , k , l ( x ) > 0 } ∣ ( 1.2 )
即为在第l l l k k k T C A V Q C , k , l ∈ [ 0 , 1 ] \mathrm{TCAVQ}_{C, k, l} \in[0,1] TCAVQ C , k , l ∈ [ 0 , 1 ] 注意,T C A V Q C , k , l \mathrm{TCAVQ}_{C, k, l} TCAVQ C , k , l S C , k , l S_{C, k, l} S C , k , l
使用CAV方法得到的图像概念如图1.2所示。
ACE
次年,automated concept-based explanation( ACE )方法[2]对CAV方法中概念提取方法 进行了改进。[2]指出了先前方法的两个缺点:
每个概念需要用户提供手工标注的图像以对其进行学习和构建。若用户了解概念的定义并且能提供相当的图像,该方法的性能良好。但所有的概念组成的空间可能是无限的,同时某些概念可能是无法明确指出的。
解释过程中可能出现用户的主观意识。用户可能不能选取正确的概念,因为概念必须由用户标注并指出。
基于此,ACE方法的主要改进点为:
对概念的自动识别
自动聚合相关图像切片
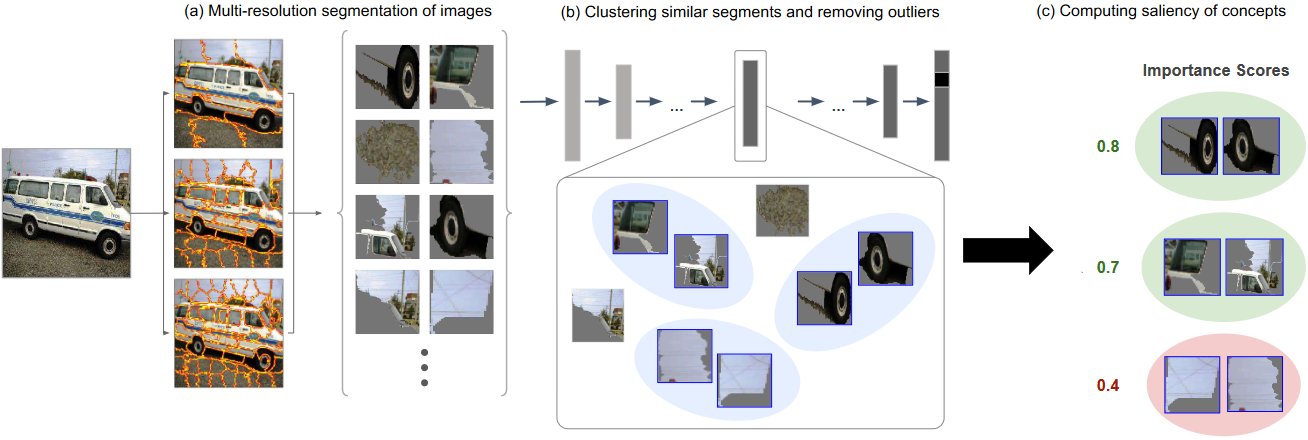
其框架如图2.1所示。具体地,该方法的执行过程分为三步。
第一步,如图2.1(a),使用三种不同的分辨率对图像进行分割,以得到不同粒度的图像切片。实际中,可以不仅仅使用三种分辨率。
第二步,如图2.1(b),将所有图像切片输入CNN,得到不同切片在中间某层的激活向量,再根据向量间的欧氏距离对其进行聚类,把不同类视为不同概念,同时丢弃离群向量。
第三步,如图2.1©,使用TCAV计算不同概念的重要性得分。
使用ACE方法得到的概念如图2.2所示。
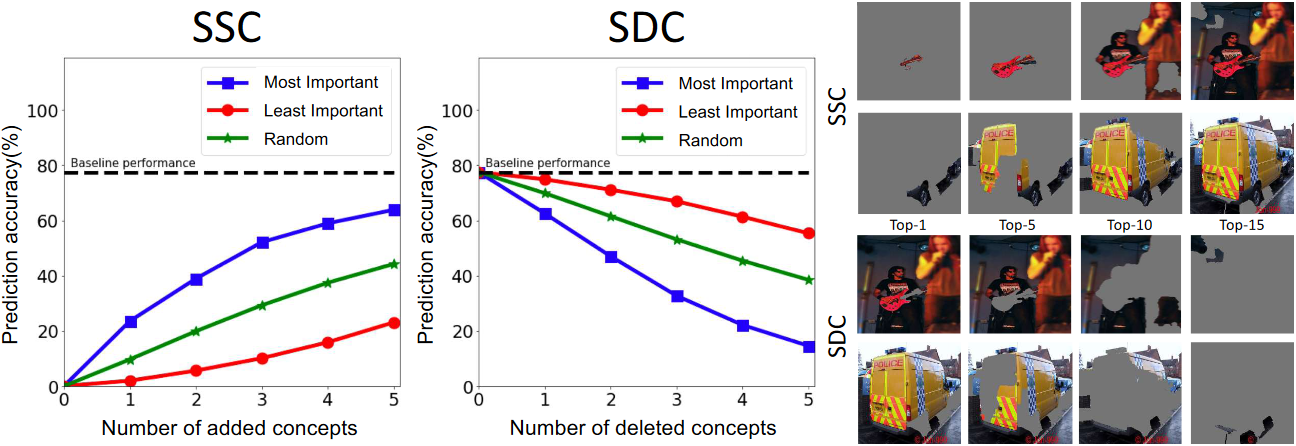
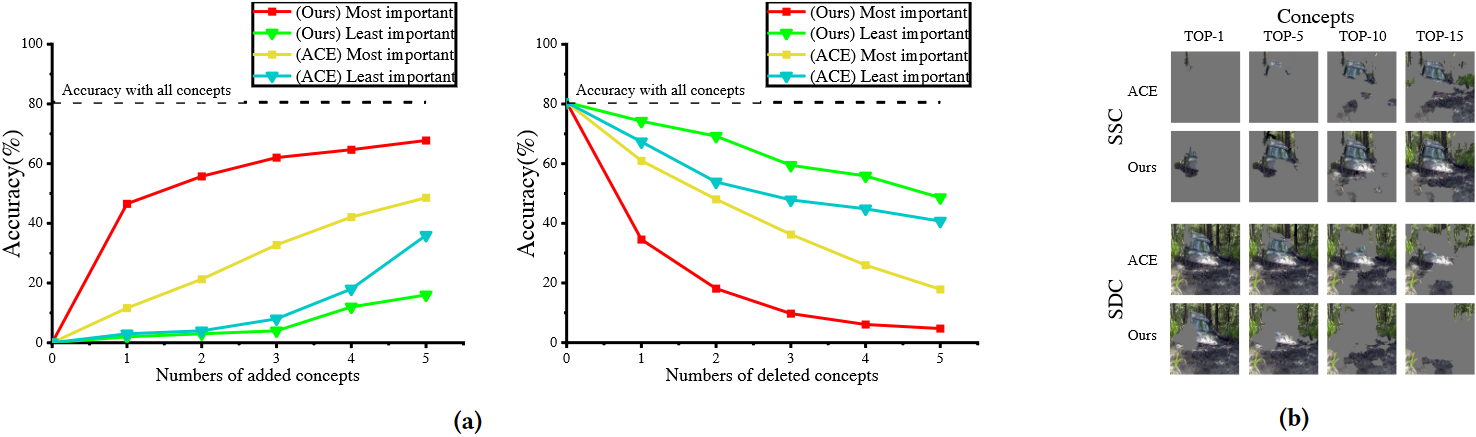
同时,[2]提出了概念的重要性评价指标,分别为smallest sufficient concepts( SSC )和smallest destroying concepts( SDC )。SSC寻找一个足以使网络能够预测出目标类别的概念最小集合,而SDC寻找一个移除这些概念后导致网络做出错误预测的最小概念集合,如图2.3所示。
CONE-SHAP
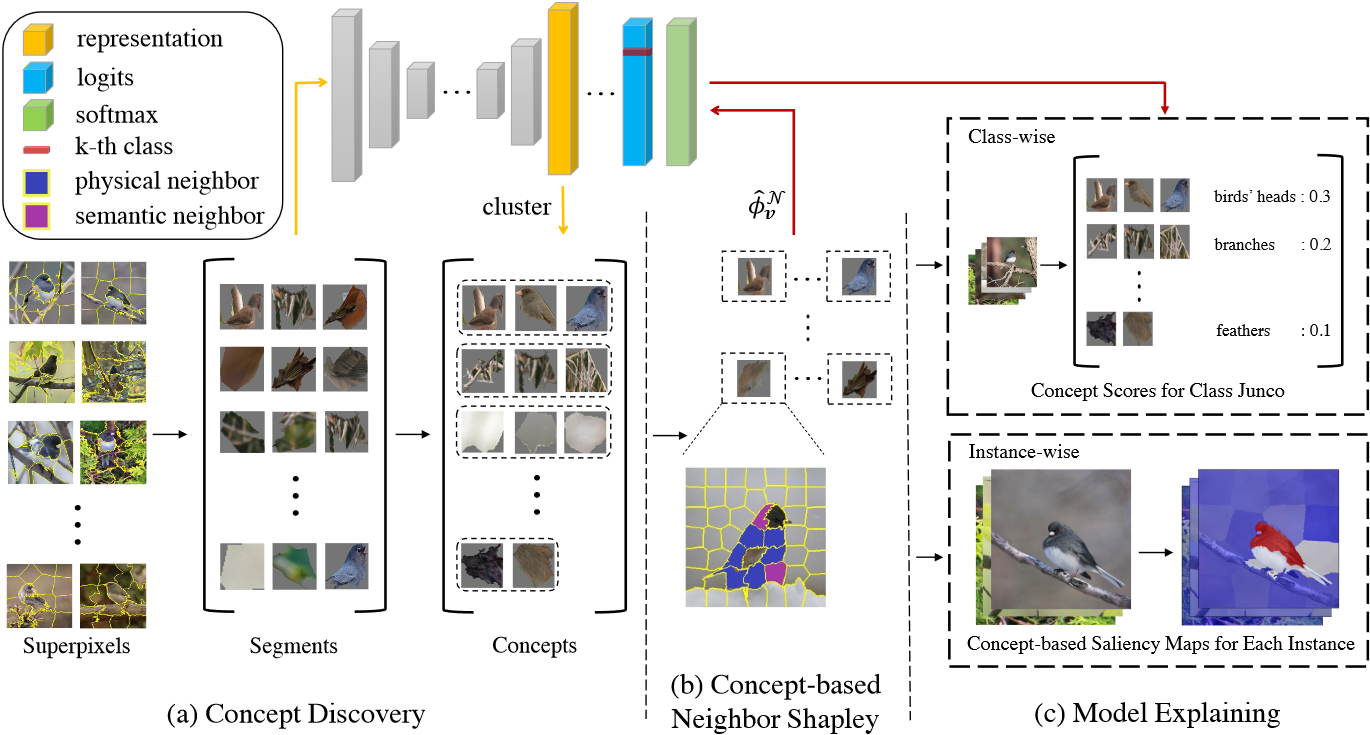
Concept-based neighbor shapley( CONE-SHAP )[3]方法是2021年对基于概念的解释方法的改进,其主要改进CAV方法中概念重要性评价方法 。该方法的主要动机有如下两点:
先前的解释方法仅将各个概念视为互相独立的组件,忽略概念之间的互动或相互关系。例如,吉他弦是吉他图像的一个重要概念,但如果图像中没有出现吉他的主体部分,神经网络则无法区分图像中的对象是吉他或小提琴。在这个例子中,吉他弦和吉他身体并非相互独立的概念,而是需要进行互动以影响网络分类决策。
CONE-SHAP使用来自于博弈论中的 shapley值来评估各个概念对于图像的重要性,改进了基于概念的解释方法的性能表现。
与 ACE 方法类似的,CONE-SHAP 将概念定义为一组具有语义相似性的图像切片,并对每个输入图像进行超像素分割,得到某个特定类别中的若干切片,再根据神经网络中的嵌入表示对这些切片进行聚类,最终获得m m m C = { C 1 , C 2 , … , C m } C=\left\{C_{1}, C_{2}, \ldots, C_{m}\right\} C = { C 1 , C 2 , … , C m } C i = { c i , 1 , c i , 2 , … , c i , ∣ C i ∣ } C_{i}=\left\{c_{i, 1}, c_{i, 2}, \ldots, c_{i,\left|C_{i}\right|}\right\} C i = { c i , 1 , c i , 2 , … , c i , ∣ C i ∣ } c i , j c_{i,j} c i , j i i i j j j ∣ C i ∣ \left|C_{i}\right| ∣ C i ∣ i i i m m m
为了衡量图像中的某个片段对解释模型的贡献,CONE-SHAP采用一种反事实的方法,即考虑如果没有这个片段,模型的预测将如何改变。对于分类任务,令g g g g k g_{k} g k k k k s s s
v k ( s ) = g k ( x ) − g k ( x \ { s } ) (3.1) v_{k}(s)=g_{k}(x)-g_{k}(x \backslash\{s\}) \tag{3.1}
v k ( s ) = g k ( x ) − g k ( x \ { s }) ( 3.1 )
为简单起见,将v k ( s ) v_{k}(s) v k ( s ) v ( s ) v(s) v ( s )
根据 Shapley 值的计算过程,将图像中的所有N N N S S S i i i S \ { i } S \backslash\{i\} S \ { i } i i i i i i S S S
Δ v ( i , S ) = v ( S ) − v ( S \ { i } ) (3.2) \Delta v(i, S)=v(S)-v(S \backslash\{i\}) \tag{3.2}
Δ v ( i , S ) = v ( S ) − v ( S \ { i }) ( 3.2 )
若将v ( ⋅ ) v(\cdot) v ( ⋅ ) Δ v ( ⋅ ) \Delta v(\cdot) Δ v ( ⋅ ) i i i
ϕ v ( i ) = 1 N ∑ j = 1 N 1 ( N − 1 j − 1 ) ∑ S ∈ S j ( i ) Δ v ( i , S ) (3.3) \phi_{v}(i)=\frac{1}{N} \sum_{j=1}^{N} \frac{1}{\left(\begin{array}{c}
N-1 \\
j-1
\end{array}\right)} \sum_{S \in S_{j}(i)} \Delta v(i, S) \tag{3.3}
ϕ v ( i ) = N 1 j = 1 ∑ N ( N − 1 j − 1 ) 1 S ∈ S j ( i ) ∑ Δ v ( i , S ) ( 3.3 )
其中S j ( i ) S_{j}(i) S j ( i ) i i i j j j
但是,由于计算Shapley值的复杂度极高,随玩家数量的指数级提高。因此,在实际中,研究者开发出了多种降低计算Shapley值复杂度的逼近方法。CONE-SHAP方法也不例外。具体地,其将每个切片视为一个玩家,令N ( i ) \mathcal{N}(i) N ( i ) i i i ( 3.3 ) (3.3) ( 3.3 )
ϕ v N ( i ) = 1 ∣ N ( i ) ∣ ∑ j = 1 ∣ N ( i ) ∣ 1 ( ∣ N ( i ) ∣ − 1 j − 1 ) ∑ i ∈ S S ⊆ N ( i ) Δ v ( i , S ) (3.4) \phi_{v}^{\mathcal{N}}(i)=\frac{1}{|\mathcal{N}(i)|} \sum_{j=1}^{|\mathcal{N}(i)|} \frac{1}{\left(\begin{array}{c}
|\mathcal{N}(i)|-1 \\
j-1
\end{array}\right)} \sum_{\substack{i \in S \\
S \subseteq \mathcal{N}(i)}} \Delta v(i, S) \tag{3.4}
ϕ v N ( i ) = ∣ N ( i ) ∣ 1 j = 1 ∑ ∣ N ( i ) ∣ ( ∣ N ( i ) ∣ − 1 j − 1 ) 1 i ∈ S S ⊆ N ( i ) ∑ Δ v ( i , S ) ( 3.4 )
又考虑到实际中,一个切片的领域可能较大,所以该方法仅从各个切片的领域中采样多个切片。具体地,从N ( i ) \mathcal{N}(i) N ( i ) k k k N k ( i ) \mathcal{N}_{k}(i) N k ( i ) M M M i i i
ϕ ^ v N ( i ) = 1 M ∣ N k ( i ) ∣ ∑ t = 1 M ∑ j = 1 ∣ N k ( i ) ∣ 1 ( ∣ N k ( i ) ∣ − 1 j − 1 ) ∑ i ∈ S S ⊆ N k ( i ) Δ v ( i , S ) (3.5) \hat{\phi}_{v}^{\mathcal{N}}(i)=\frac{1}{M\left|\mathcal{N}_{k}(i)\right|} \sum_{t=1}^{M} \sum_{j=1}^{\left|\mathcal{N}_{k}(i)\right|} \frac{1}{\left(\begin{array}{c}
\left|\mathcal{N}_{k}(i)\right|-1 \\
j-1
\end{array}\right)} \sum_{\substack{i \in S \\
S \subseteq \mathcal{N}_{k}(i)}} \Delta v(i, S) \tag{3.5}
ϕ ^ v N ( i ) = M ∣ N k ( i ) ∣ 1 t = 1 ∑ M j = 1 ∑ ∣ N k ( i ) ∣ ( ∣ N k ( i ) ∣ − 1 j − 1 ) 1 i ∈ S S ⊆ N k ( i ) ∑ Δ v ( i , S ) ( 3.5 )
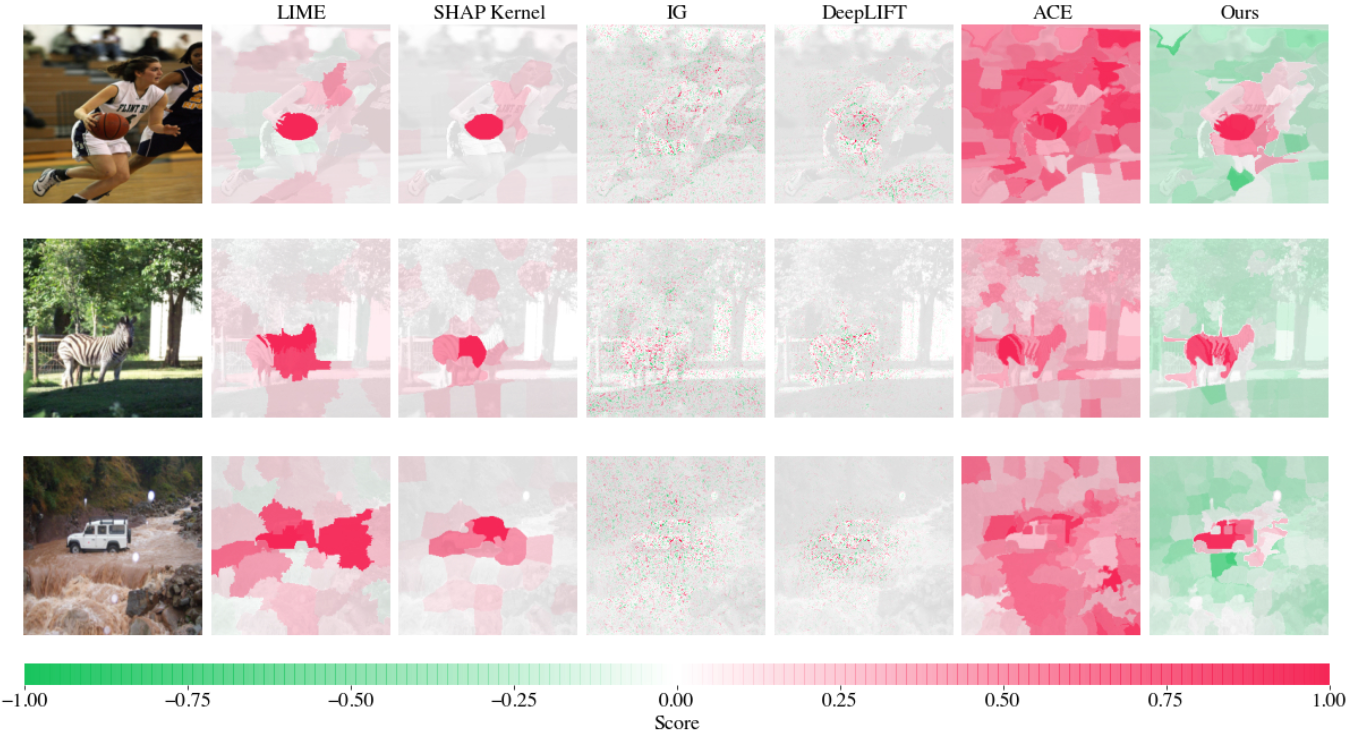
CONE-SHAP方法的输出显著图如图3.2所示。
同时,该方法的SSC和SDC评价曲线如图3.3所示。
VCE
Visual concept extractor( VCE )[4]是提出的框架中的一个部分,用于提取图像概念。VCE是ACE的改进方法,其动机是当表示一个概念的图像数量不足时,ACE方法提取到的概念往往是图像中的背景信息,即概念提取错误,如图4.1(左)所示。因此,该方法将图像中的背景像素抹去,留下前景像素,以促使概念正确提取图像中的物体。
VCE方法首先使用Grad-CAM算法,生成一个特定类别的显著图M M M τ \tau τ M M M τ \tau τ τ \tau τ M M M M ˉ \bar{M} M ˉ I I I I ˉ = I × M ˉ \bar{I}=I \times \bar{M} I ˉ = I × M ˉ × \times ×
NCAV
Non-negative concept activation vectors( NCAV )[5]将非负矩阵分解引入概念提取中。该方法指出了先前方法的两个缺点,同时改进了CAV的概念提取和重要性评价方法 :
对于不同图像,学习得到的概念权重不一致。由于先前方法仅仅是对卷积网络模型的线性近似,因此这一现象是相当普遍的。
评价学习到的CAV的性能存在困难。
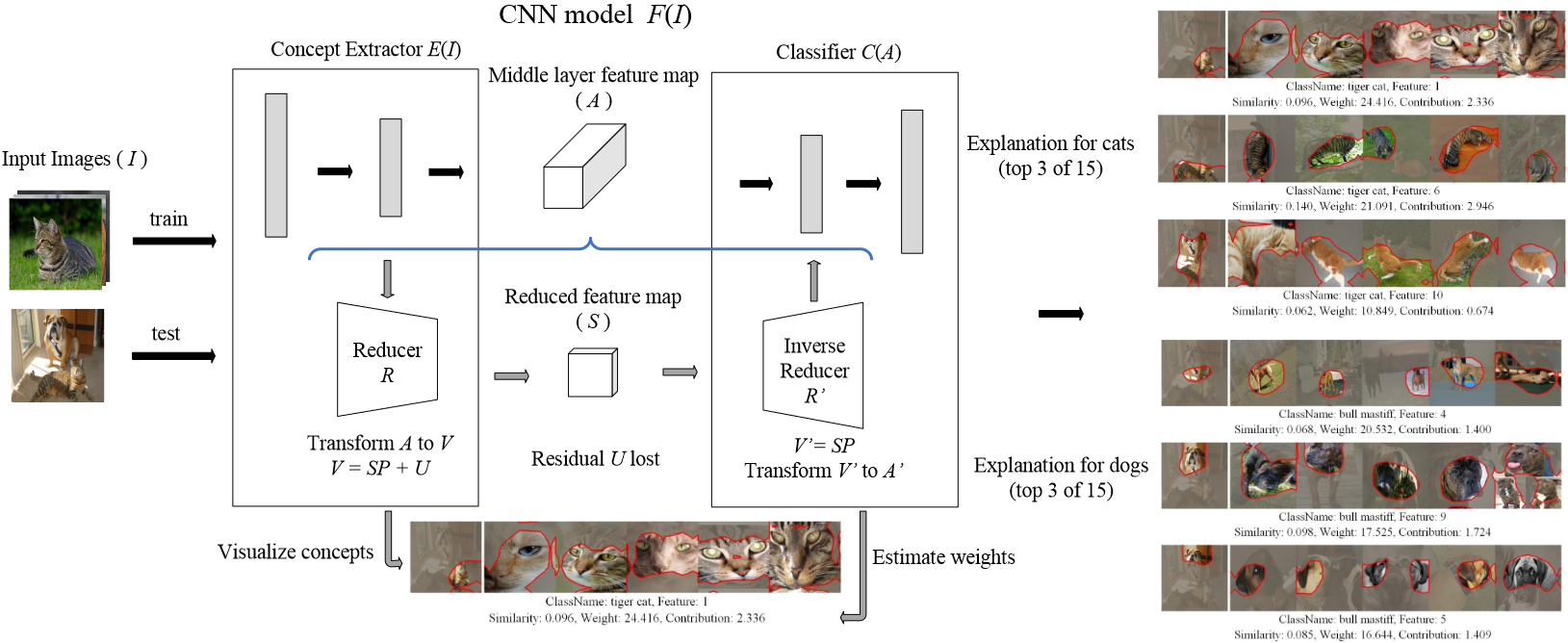
除了非负矩阵变换,NCAV方法还将ACE方法中的聚类操作替换为一个reducer模块。这种做法的优点是reducer提供概念的分数作为输出,而不是对聚类中心点的预测。这一概念分数可以应用于近似模型,以更准确地分析每个特征的贡献分布,在还原过程中提供了更好的保真度。NCAV的框架如图5.1所示。
给定一个预训练后的CNN分类器F F F n n n I I I F ( I ) = Y F(I)=Y F ( I ) = Y y y y l l l A A A F F F E l ( I ) = A l E_{l}(I)=A_{l} E l ( I ) = A l C l ( A l ) = Y C_{l}\left(A_{l}\right)=Y C l ( A l ) = Y A A A r e l u relu re l u n × h × w × c n \times h \times w \times c n × h × w × c h h h w w w c c c a ( i , j ) a^{(i,j)} a ( i , j ) A A A ( i , j ) ( 0 ≤ i < h , 0 ≤ j < w ) (i,j)(0 \leq i<h, 0 \leq j<w) ( i , j ) ( 0 ≤ i < h , 0 ≤ j < w ) a a a 将a a a ,对这些向量进行分解,可以得到概念的重要信息。
首先,NCAV将特征图A A A V ∈ R ( n × h × w ) × c V \in R^{(n \times h \times w) \times c} V ∈ R ( n × h × w ) × c c c c c ′ c^{\prime} c ′ V = S P + U V=S P+U V = SP + U S ∈ R ( n × h × w ) × c ′ S \in R^{(n \times h \times w) \times c^{\prime}} S ∈ R ( n × h × w ) × c ′ P ∈ R c ′ × c P \in R^{c^{\prime} \times c} P ∈ R c ′ × c U U U
min S , P ∥ V − S P ∥ F s.t. S ≥ 0 , P ≥ 0 (5.1) \min _{S, P}\|V-S P\|_{F} \quad \text { s.t. } \quad S \geq 0, P \geq 0 \tag{5.1}
S , P min ∥ V − SP ∥ F s.t. S ≥ 0 , P ≥ 0 ( 5.1 )
在训练完成后,矩阵P P P S S S P P P
其次,计算特征的权重。对于一个已经学习到的第l l l p l p_{l} p l A l A_{l} A l k k k
∂ C l , k ∂ p l = 1 n × h × w ∑ a ∈ A l lim ϵ → 0 h l , k ( a + ϵ p l ) − h l , k ( a − ϵ p l ) 2 ϵ (5.2) \frac{\partial C_{l, k}}{\partial p_{l}}=\frac{1}{n \times h \times w} \sum_{a \in A_{l}} \lim _{\epsilon \rightarrow 0} \frac{h_{l, k}\left(a+\epsilon p_{l}\right)-h_{l, k}\left(a-\epsilon p_{l}\right)}{2 \epsilon}\tag{5.2}
∂ p l ∂ C l , k = n × h × w 1 a ∈ A l ∑ ϵ → 0 lim 2 ϵ h l , k ( a + ϵ p l ) − h l , k ( a − ϵ p l ) ( 5.2 )
[5]建议将l l l C C C
C k , l ( A ) = G A P ( A ) W + b = G A P ( S ) P W + G A P ( U ) W + b (5.3) \begin{aligned}
C_{k, l}(A) &=G A P(A) W+b \\
&=G A P(S) P W+G A P(U) W+b
\end{aligned} \tag{5.3}
C k , l ( A ) = G A P ( A ) W + b = G A P ( S ) P W + G A P ( U ) W + b ( 5.3 )
其中,W W W b b b
最后,计算概念的权重。对每个概念NCAV,其权重即为P W PW P W
CGL
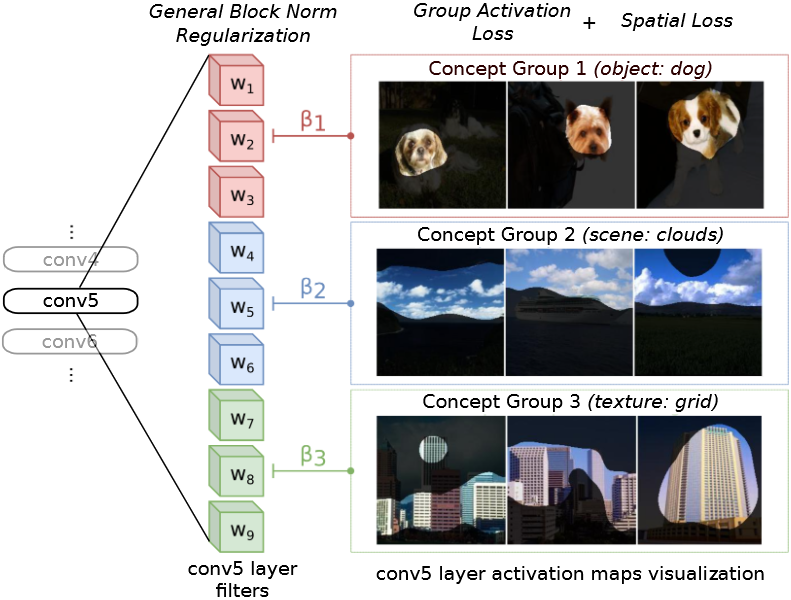
Concept group learning( CGL )[6]认为先前的很多工作集中在理解CNN的隐藏解释上,但缺乏主动影响学习过程以利于可解释的表征的工作。
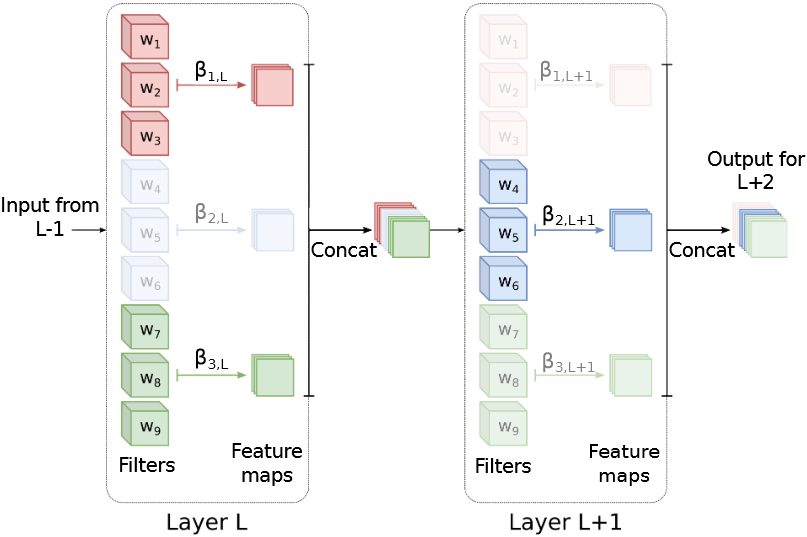
为了解决这个问题,作者提出了CGL,其不仅可以评估可解释性,而且可以诱导 可解释性,如图6.1所示。具体地,CGL是在训练时诱导CNN的群体结构,在训练过程中出现具有相关语义的卷积核集,并通过精心选择的正则化和辅助损失函数来实现这一点。在CGL中,在进行任何训练之前,其将每一层的卷积核划分为若干组,称之为概念组。在训练过程中,促进同一概念组中的卷积核学习类似的特征,以形成了一组相似的卷积核,共同编码一个抽象的视觉概念(例如,一个物体、场景或颜色)。
设卷积网络中的卷积核数量为F F F G G G ( 1 , … , f ) , ( f + 1 , … , 2 f ) , … ( ( G − 1 ) f + 1 , … , G f ) (1, \ldots, f),(f+1, \ldots, 2 f), \ldots((G-1) f+1, \ldots, G f) ( 1 , … , f ) , ( f + 1 , … , 2 f ) , … (( G − 1 ) f + 1 , … , G f ) F = G f F=Gf F = G f
组激活损失L g L_g L g
组激活损失促使同一组内的所有卷积核在输入图像大致相同的区域保持激活状态,即输出激活值较大。通过将卷积核的输出激活值先进行放缩再经过sigmoid函数,CGL定义了一个卷积核在图像某个区域是否是激活的。令第l l l g g g i i i a i g l ∈ R A l a_{ig}^{l} \in \mathbb{R}^{A_{l}} a i g l ∈ R A l ψ i g l ∈ ( 0 , 1 ) A l \psi_{i g}^{l} \in(0,1)^{A_{l}} ψ i g l ∈ ( 0 , 1 ) A l
ψ i g l = σ ( P 1 a i g l S i g l + P 2 ) (6.1) \psi_{i g}^{l}=\sigma\left(P_{1} \frac{a_{i g}^{l}}{S_{i g}^{l}}+P_{2}\right) \tag{6.1}
ψ i g l = σ ( P 1 S i g l a i g l + P 2 ) ( 6.1 )
其中,S i g l S_{ig}^{l} S i g l g g g i i i P 1 P_1 P 1 P 2 P_2 P 2 ψ 1 \psi_1 ψ 1 ψ 2 \psi_2 ψ 2
D ( ψ 1 , ψ 2 ) = 2 ∥ ψ 1 − ψ 2 ∥ 1 ∥ ψ 1 ∥ 1 + ∥ ψ 2 ∥ 1 + ∥ ψ 2 − ψ 1 ∥ 1 (6.2) \mathcal{D}\left(\psi_{1}, \psi_{2}\right)=\frac{2\left\|\psi_{1}-\psi_{2}\right\|_{1}}{\left\|\psi_{1}\right\|_{1}+\left\|\psi_{2}\right\|_{1}+\left\|\psi_{2}-\psi_{1}\right\|_{1}}\tag{6.2}
D ( ψ 1 , ψ 2 ) = ∥ ψ 1 ∥ 1 + ∥ ψ 2 ∥ 1 + ∥ ψ 2 − ψ 1 ∥ 1 2 ∥ ψ 1 − ψ 2 ∥ 1 ( 6.2 )
其中,∥ ψ 1 ∥ 1 \left\|\psi_{1}\right\|_{1} ∥ ψ 1 ∥ 1 L 1 L^1 L 1 1 − I O U 1-IOU 1 − I O U
L g = 1 r ∑ l , g ∑ ( i , j ) ∈ R 2 ∥ ψ j g l − ψ i g l ∥ 1 ∑ l , g ∑ ( i , j ) ∈ R ∥ ψ j g l ∥ 1 + ∥ ψ i g l ∥ 1 + ∥ ψ j g l − ψ i g l ∥ 1 + ⋯ λ 2 1 r ∑ l , g ∑ ( i , j ) ∈ R 2 ∥ ψ j g l − ψ i g l + 1 ∥ 1 ∑ l , g ∑ ( i , j ) ∈ R ∥ ψ j g l ∥ 1 + ∥ ψ i g l + 1 ∥ 1 + ∥ ψ j g l − ψ i g l + 1 ∥ 1 (6.3) \begin{array}{l}
L_g = \frac{1}{r} \frac{\sum_{l, g} \sum_{(i, j) \in \mathcal{R}} \quad 2\left\|\psi_{j g}^{l}-\psi_{i g}^{l}\right\|_{1}}{\sum_{l, g} \sum_{(i, j) \in \mathcal{R}}\left\|\psi_{j g}^{l}\right\|_{1}+\left\|\psi_{i g}^{l}\right\|_{1}+\left\|\psi_{j g}^{l}-\psi_{i g}^{l}\right\|_{1}}+\cdots \\
\lambda_{2} \frac{1}{r} \frac{\sum_{l, g} \sum_{(i, j) \in \mathcal{R}} \quad 2\left\|\psi_{j g}^{l}-\psi_{i g}^{l+1}\right\|_{1}}{\sum_{l, g} \sum_{(i, j) \in \mathcal{R}}\left\|\psi_{j g}^{l}\right\|_{1}+\left\|\psi_{i g}^{l+1}\right\|_{1}+\left\|\psi_{j g}^{l}-\psi_{i g}^{l+1}\right\|_{1}}
\end{array} \tag{6.3}
L g = r 1 ∑ l , g ∑ ( i , j ) ∈ R ∥ ψ j g l ∥ 1 + ∥ ψ i g l ∥ 1 + ∥ ψ j g l − ψ i g l ∥ 1 ∑ l , g ∑ ( i , j ) ∈ R 2 ∥ ψ j g l − ψ i g l ∥ 1 + ⋯ λ 2 r 1 ∑ l , g ∑ ( i , j ) ∈ R ∥ ψ j g l ∥ 1 + ∥ ψ i g l + 1 ∥ 1 + ∥ ψ j g l − ψ i g l + 1 ∥ 1 ∑ l , g ∑ ( i , j ) ∈ R 2 ∥ ψ j g l − ψ i g l + 1 ∥ 1 ( 6.3 )
其中,R \mathcal{R} R { 1 , 2 , … , N g l } × { 1 , 2 , … , N g l } \left\{1,2, \ldots, N_{g}^{l}\right\} \times\left\{1,2, \ldots, N_{g}^{l}\right\} { 1 , 2 , … , N g l } × { 1 , 2 , … , N g l } N g l N_g^l N g l l l l g g g r r r r = 3 N g l r=3N_g^l r = 3 N g l λ 2 \lambda_2 λ 2 0 0 0
空间损失L S L_S L S
为避免某组卷积核学习太大范围内的空间概念,从而造成概念混淆,该损失通过惩罚相隔较远的激活中心,以促使卷积核只在图像中的一小块区域激活,其具体定义如下:
L s ( ψ ) = ∑ j ψ j ∥ j − c ( ψ ) ∥ 2 ∑ j ψ j , where c ( ψ ) = ∑ j j ⋅ ψ j ∑ j ψ j (6.4) \mathrm{L}_{\mathrm{s}}(\psi)=\frac{\sum_{j} \psi_{j}\|j-c(\psi)\|_{2}}{\sum_{j} \psi_{j}}, \text { where } c(\psi)=\frac{\sum_{j} j \cdot \psi_{j}}{\sum_{j} \psi_{j}} \tag{6.4}
L s ( ψ ) = ∑ j ψ j ∑ j ψ j ∥ j − c ( ψ ) ∥ 2 , where c ( ψ ) = ∑ j ψ j ∑ j j ⋅ ψ j ( 6.4 )
其中下标j j j c c c
整体块正则R b n R_{bn} R bn
使用整体块正则R b n R_{bn} R bn
记w g l w_{gl} w g l l l l g g g R b n R_{bn} R bn
R b n = ∑ l = 1 L ∑ g = 1 G ∥ w g l ∥ F r (6.5) \mathrm{R}_{\mathrm{bn}}=\sum_{l=1}^{L} \sum_{g=1}^{G}\left\|w_{g l}\right\|_{\mathrm{Fr}}\tag{6.5}
R bn = l = 1 ∑ L g = 1 ∑ G ∥ w g l ∥ Fr ( 6.5 )
其中,L L L G G G ∥ ⋅ ∥ F r \|\cdot\| _{F r} ∥ ⋅ ∥ F r M M M ∥ M ∥ F r 2 = ∑ i , j M i , j 2 \|M\|_{\mathrm{Fr}}^{2}=\sum_{i, j} M_{i, j}^{2} ∥ M ∥ Fr 2 = ∑ i , j M i , j 2
β g l = ∥ w g l ∥ F r and β l = ∑ g = 1 G β g l (6.6) \beta_{g l}=\left\|w_{g l}\right\|_{\mathrm{Fr}} \quad \text { and } \quad \beta_{l}=\sum_{g=1}^{G} \beta_{g l} \tag{6.6}
β g l = ∥ w g l ∥ Fr and β l = g = 1 ∑ G β g l ( 6.6 )
其中,β g l \beta_{g l} β g l l l l β l \beta_{l} β l l l l
综上,网络的总损失函数为
L = L d ( w ) + λ b n R b n ( w ) + λ g L g ( ψ ) + λ s L s ( ψ ) (6.7) \mathbf{L}=L_{d}(w)+\lambda_{b n} \mathrm{R}_{\mathrm{bn}}(w)+\lambda_{g} \mathrm{~L}_{\mathrm{g}}(\psi)+\lambda_{s} \mathrm{~L}_{\mathrm{s}}(\psi) \tag{6.7}
L = L d ( w ) + λ bn R bn ( w ) + λ g L g ( ψ ) + λ s L s ( ψ ) ( 6.7 )
其中为简化公式,使用w w w ψ \psi ψ λ b n \lambda_{bn} λ bn λ g \lambda_{g} λ g λ s \lambda_{s} λ s
AutoRMI
Automatic and robust model interpretation method( AutoRMI )[7]是AAAI-2022上最新提出的基于概念的自解释模型。该模型的动机来自于以下两点:
先前的基于概念的方法需要人工干预。这一点在本文前面已经被多次强调。具体来说有两个需要干预的地方,一是需要人类通过使用一组输入实例来手动定义概念,二是手动计算每个预先定义的概念的重要性得分。
解释的鲁棒性需要关注。
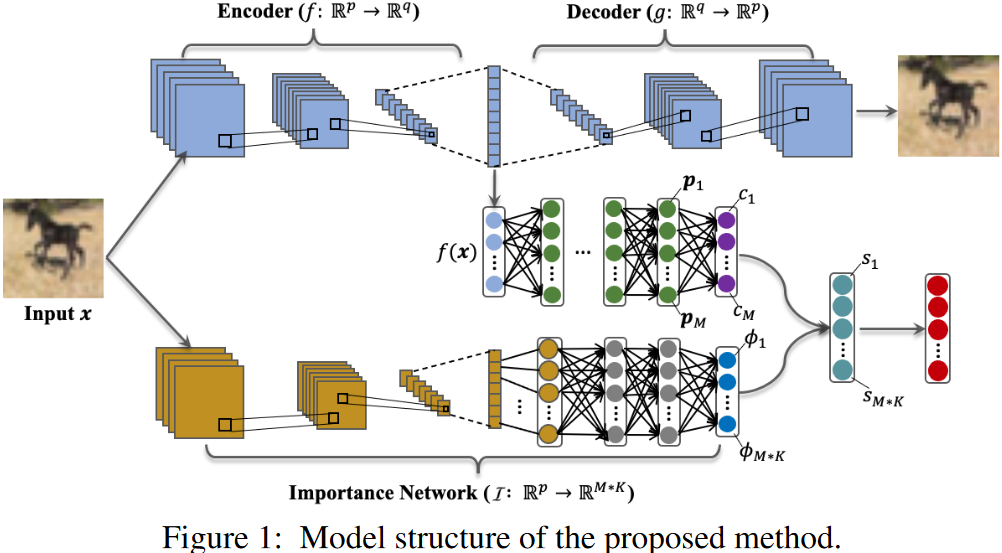
基于此,该方法的目标即为构建一个自动的且鲁棒的自解释模型,其框架如图8.1所示。
记训练数据集为X = ( x i , y i ) i = 1 N X={(x_{i},y_{i})}_{i=1}^{N} X = ( x i , y i ) i = 1 N x i ∈ R p x_{i} \in \mathbb{R}^{p} x i ∈ R p y i ∈ 1 , . . . , K y_{i} \in {1,...,K} y i ∈ 1 , ... , K
自编码器网络使用编码器网络学习一个输入图像的低维表示,即f : R p → R q f:\mathbb{R}^{p} \rightarrow \mathbb{R}^{q} f : R p → R q g : R q → R p g:\mathbb{R}^{q} \rightarrow \mathbb{R}^{p} g : R q → R p
概念网络将学习到的图像低维表示转化为概念,即h : R q → R K h:\mathbb{R}^{q} \rightarrow \mathbb{R}^{K} h : R q → R K M M M { p m ∈ R q } m = 1 M \{p_{m} \in \mathbb{R}^{q}\}_{m=1}^{M} { p m ∈ R q } m = 1 M c m = ∥ f ( x ) − p m ∥ 2 2 c_{m}=\left\|f(\boldsymbol{x})-\boldsymbol{p}_{m}\right\|_{2}^{2} c m = ∥ f ( x ) − p m ∥ 2 2 c ( x ) c(x) c ( x )
重要性网络(I : R q → R M ∗ K \mathcal{I}: \mathbb{R}^{q} \rightarrow \mathbb{R}^{M*K} I : R q → R M ∗ K y ( x ) = h ( f ( x ) ) y(\boldsymbol{x})=h(f(\boldsymbol{x})) y ( x ) = h ( f ( x )) Φ ( x ) = [ ϕ 1 ( x ) , ϕ 2 ( x ) , ⋯ , ϕ M ∗ K ( x ) ] \boldsymbol{\Phi}(\boldsymbol{x})=\left[\phi_{1}(\boldsymbol{x}), \phi_{2}(\boldsymbol{x}), \cdots, \phi_{M * K}(\boldsymbol{x})\right] Φ ( x ) = [ ϕ 1 ( x ) , ϕ 2 ( x ) , ⋯ , ϕ M ∗ K ( x ) ]
最后,聚合相似性向量与重要性向量用于分类。
构建该网络的损失函数有如下几个:
重建损失。重建损失促使自编码器输出与输入图像尽量相同的图像,其表达式为
L 1 ( { x i } i = 1 N , { x ~ i } i = 1 N ) = ∑ i = 1 N ∥ x i − g ( f ( x i ) ) ∥ 2 2 (7.1) \mathcal{L}_{1}\left(\left\{\boldsymbol{x}_{i}\right\}_{i=1}^{N},\left\{\tilde{\boldsymbol{x}}_{i}\right\}_{i=1}^{N}\right)=\sum_{i=1}^{N}\left\|\boldsymbol{x}_{i}-g\left(f\left(\boldsymbol{x}_{i}\right)\right)\right\|_{2}^{2} \tag{7.1}
L 1 ( { x i } i = 1 N , { x ~ i } i = 1 N ) = i = 1 ∑ N ∥ x i − g ( f ( x i ) ) ∥ 2 2 ( 7.1 )
其中,x ~ i \tilde{\boldsymbol{x}}_{i} x ~ i x i x_{i} x i
解释性惩罚项。该项旨在使学习到的概念更容易被人类理解、更具解释性,其表达式为
L 2 ( { p m } m = 1 M , { x i } i = 1 N ) = 1 M ∑ m = 1 M min i ∈ [ 1 , N ] ∥ p m − f ( x i ) ∥ 2 2 + 1 N ∑ i = 1 N min m ∈ [ 1 , M ] ∥ f ( x i ) − p m ∥ 2 2 + 2 M ( M − 1 ) ∑ m = 1 M ∑ m ~ = m + 1 M max ( 0 , d m i n − ∥ p m − p m ~ ∥ 2 ) 2 (7.2) \begin{array}{c}
\mathcal{L}_{2}\left(\left\{\boldsymbol{p}_{m}\right\}_{m=1}^{M},\left\{\boldsymbol{x}_{i}\right\}_{i=1}^{N}\right)=\frac{1}{M} \sum_{m=1}^{M} \min _{i \in[1, N]}\left\|\boldsymbol{p}_{m}-f\left(\boldsymbol{x}_{i}\right)\right\|_{2}^{2} \\
+\frac{1}{N} \sum_{i=1}^{N} \min _{m \in[1, M]}\left\|f\left(\boldsymbol{x}_{i}\right)-\boldsymbol{p}_{m}\right\|_{2}^{2}+\frac{2}{M(M-1)} \sum_{m=1}^{M} \sum_{\tilde{m}=m+1}^{M} \\
\max \left(0, d_{m i n}-\left\|\boldsymbol{p}_{m}-\boldsymbol{p}_{\tilde{m}}\right\|_{2}\right)^{2}
\end{array} \tag{7.2}
L 2 ( { p m } m = 1 M , { x i } i = 1 N ) = M 1 ∑ m = 1 M min i ∈ [ 1 , N ] ∥ p m − f ( x i ) ∥ 2 2 + N 1 ∑ i = 1 N min m ∈ [ 1 , M ] ∥ f ( x i ) − p m ∥ 2 2 + M ( M − 1 ) 2 ∑ m = 1 M ∑ m ~ = m + 1 M max ( 0 , d min − ∥ p m − p m ~ ∥ 2 ) 2 ( 7.2 )
其中,d m i n d_{min} d min p m p_{m} p m c c c
误分类损失。误分类损失促使网络的分类预测尽量正确,其表达式为
L 3 = 1 N ∑ i = 1 N ∑ k = 1 K L y ( h k ( f ( x i ) ) , y i ) (7.3) \mathcal{L}_{3}=\frac{1}{N} \sum_{i=1}^{N} \sum_{k=1}^{K} L_{y}\left(h_{k}\left(f\left(\boldsymbol{x}_{i}\right)\right), y_{i}\right) \tag{7.3}
L 3 = N 1 i = 1 ∑ N k = 1 ∑ K L y ( h k ( f ( x i ) ) , y i ) ( 7.3 )
其中,L y L_{y} L y
鲁棒解释正则项。该项旨在使网络的解释更加鲁棒,其表达式为
L 4 = 1 N ∑ i = 1 N max ( min j ∈ S x i , k ϕ ‾ j ( x i ) − max j ˉ ∈ S ~ x i , k ϕ ˉ j ˉ ( x i ) , 0 ) (7.4) \mathcal{L}_{4}=\frac{1}{N} \sum_{i=1}^{N} \max \left(\min _{j \in S_{\boldsymbol{x}_{i}, k}} \underline{\phi}_{j}\left(\boldsymbol{x}_{i}\right)-\max _{\bar{j} \in \tilde{S}_{\boldsymbol{x}_{i}, k}} \bar{\phi}_{\bar{j}}\left(\boldsymbol{x}_{i}\right), 0\right) \tag{7.4}
L 4 = N 1 i = 1 ∑ N max ( j ∈ S x i , k min ϕ j ( x i ) − j ˉ ∈ S ~ x i , k max ϕ ˉ j ˉ ( x i ) , 0 ) ( 7.4 )
综上,该模型的总损失函数为
L = 1 N ∑ i = 1 N ∑ k = 1 K L y ( h k ( f ( x i ) ) , y i ) + λ 1 ∑ i = 1 N ∥ x i − g ( f ( x i ) ) ∥ 2 2 + λ 2 M ∑ m = 1 M min i ∈ [ 1 , N ] ∥ p m − f ( x i ) ∥ 2 2 + λ 3 N ∑ i = 1 N min m ∈ [ 1 , M ] ∥ f ( x i ) − p m ∥ 2 2 + 2 λ 4 M ( M − 1 ) ∑ m = 1 M ∑ m ~ = m + 1 M max ( 0 , d m i n − ∥ p m − p m ~ ∥ 2 ) 2 + λ 5 1 N ∑ i = 1 N max ( min j ∈ S x i , k ϕ ‾ j ( x i ) − max j ˉ ∈ S ~ x i , k ϕ ˉ j ˉ ( x i ) , 0 ) , (7.5) \begin{array}{l}
\mathcal{L}=\frac{1}{N} \sum_{i=1}^{N} \sum_{k=1}^{K} L_{y}\left(h_{k}\left(f\left(\boldsymbol{x}_{i}\right)\right), y_{i}\right)+\lambda_{1} \sum_{i=1}^{N}\left\|\boldsymbol{x}_{i}-g\left(f\left(\boldsymbol{x}_{i}\right)\right)\right\|_{2}^{2} \\
+\frac{\lambda_{2}}{M} \sum_{m=1}^{M} \min _{i \in[1, N]}\left\|\boldsymbol{p}_{m}-f\left(\boldsymbol{x}_{i}\right)\right\|_{2}^{2}+\frac{\lambda_{3}}{N} \sum_{i=1}^{N} \min _{m \in[1, M]} \| f\left(\boldsymbol{x}_{i}\right)- \\
\boldsymbol{p}_{m} \|_{2}^{2}+\frac{2 \lambda_{4}}{M(M-1)} \sum_{m=1}^{M} \sum_{\tilde{m}=m+1}^{M} \max \left(0, d_{m i n}-\left\|\boldsymbol{p}_{m}-\boldsymbol{p}_{\tilde{m}}\right\|_{2}\right)^{2} \\
+\lambda_{5} \frac{1}{N} \sum_{i=1}^{N} \max \left(\min _{j \in S_{\boldsymbol{x}_{i}, k}} \underline{\phi}_{j}\left(\boldsymbol{x}_{i}\right)-\max _{\bar{j} \in \tilde{S}_{\boldsymbol{x}_{i}, k}} \bar{\phi}_{\bar{j}}\left(\boldsymbol{x}_{i}\right), 0\right),
\end{array}\tag{7.5}
L = N 1 ∑ i = 1 N ∑ k = 1 K L y ( h k ( f ( x i ) ) , y i ) + λ 1 ∑ i = 1 N ∥ x i − g ( f ( x i ) ) ∥ 2 2 + M λ 2 ∑ m = 1 M min i ∈ [ 1 , N ] ∥ p m − f ( x i ) ∥ 2 2 + N λ 3 ∑ i = 1 N min m ∈ [ 1 , M ] ∥ f ( x i ) − p m ∥ 2 2 + M ( M − 1 ) 2 λ 4 ∑ m = 1 M ∑ m ~ = m + 1 M max ( 0 , d min − ∥ p m − p m ~ ∥ 2 ) 2 + λ 5 N 1 ∑ i = 1 N max ( min j ∈ S x i , k ϕ j ( x i ) − max j ˉ ∈ S ~ x i , k ϕ ˉ j ˉ ( x i ) , 0 ) , ( 7.5 )
其中,λ 1 \lambda_{1} λ 1 λ 2 \lambda_{2} λ 2 λ 3 \lambda_{3} λ 3 λ 4 \lambda_{4} λ 4 λ 5 \lambda_{5} λ 5
参考文献
[1] Kim, Been, et al. “Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav).” International conference on machine learning . PMLR, 2018.
[2] Ghorbani, Amirata, et al. “Towards automatic concept-based explanations.” Advances in Neural Information Processing Systems 32 (2019).
[3] Li, Jiahui, et al. “Instance-wise or Class-wise? A Tale of Neighbor Shapley for Concept-based Explanation.” Proceedings of the 29th ACM International Conference on Multimedia. 2021.
[4] Ge, Yunhao, et al. “A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 2021.
[5] Zhang, Ruihan, et al. “Invertible Concept-based Explanations for CNN Models with Non-negative Concept Activation Vectors.” Proceedings of the AAAI Conference on Artificial Intelligence . Vol. 35. No. 13. 2021.
[6] Varshneya, Saurabh, et al. “Learning Interpretable Concept Groups in CNNs.” arXiv preprint arXiv:2109.10078 (2021).
[7] Huai, Mengdi, et al. “Towards Automating Model Explanations with Certified Robustness Guarantees.” (2022).







 微信
微信 支付宝
支付宝