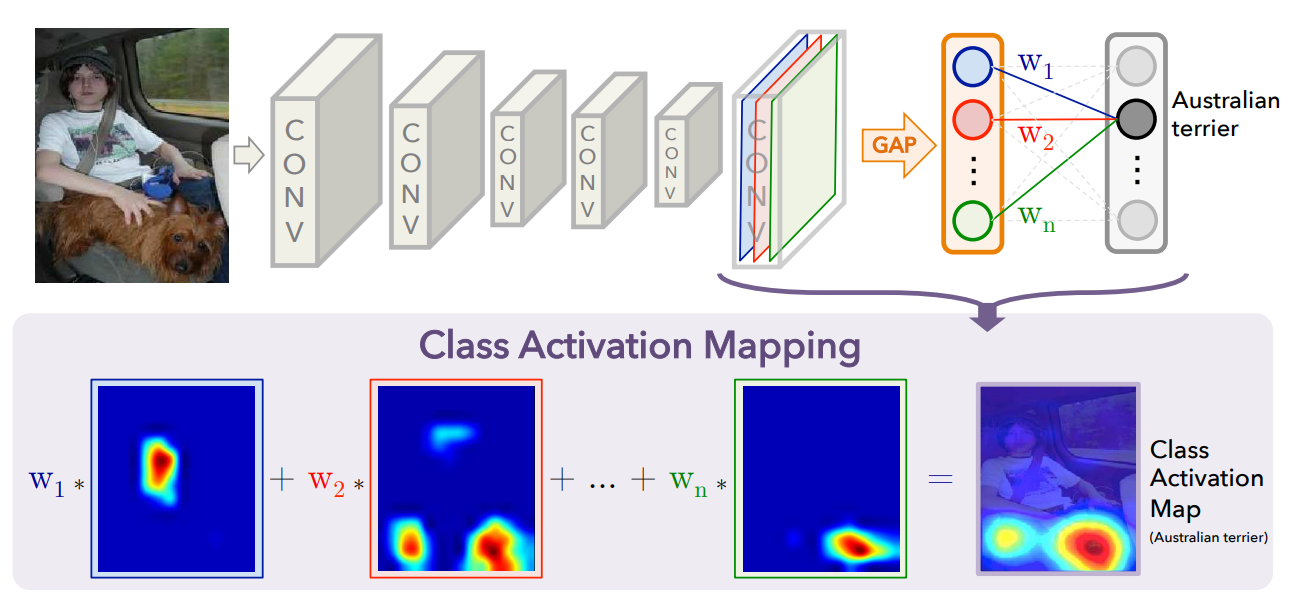
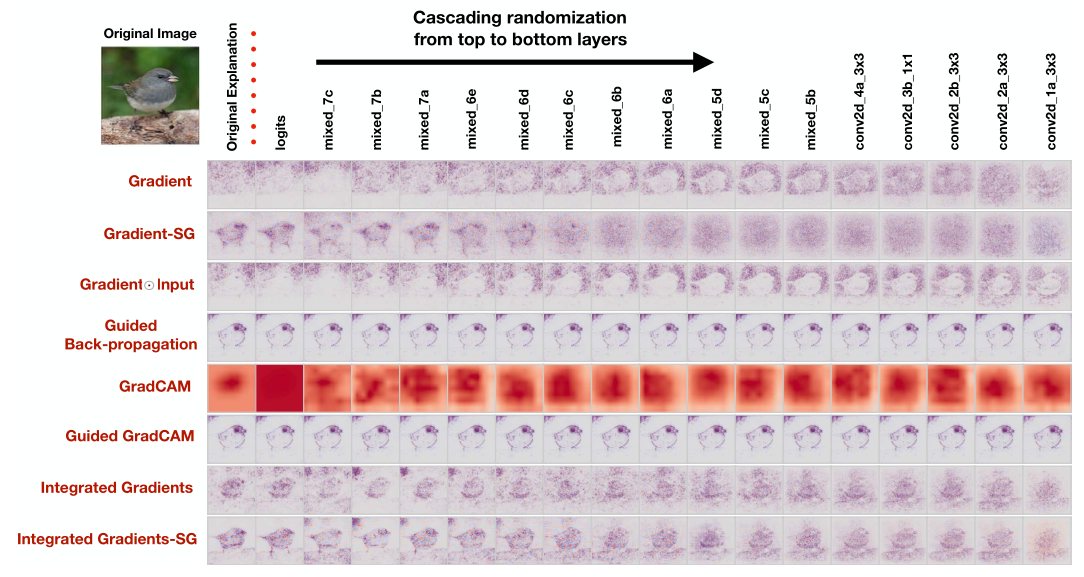
显著图的相关工作
前言
撰写本文的目的是为了总结在日常阅读论文算法的各个比较算法。通常在论文的实验部分,作者会将自己提出的算法与之前的算法进行比较。本文即为这些算法做统一梳理,从过去的论文中学习显著图这一研究领域的进展。
类激活映射方法
GradCAM++
简介
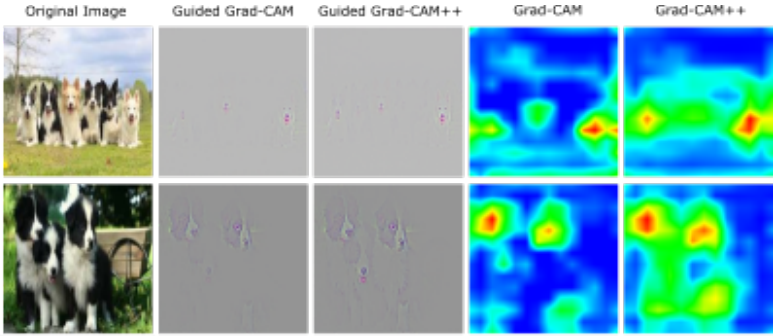
GradCAM++[1]是对经典的GradCAM[2]算法的改进。[1]的motivation是如果输入图像中同一类别的物体多次出现,GradCAM不能正确地定位图像中的各个物体,如图所示。
方法
令为最尾卷积层的第个特征图,GradCAM算法计算的类激活映射为
其中,对每个特定的特征图的权重由下式计算
这里是特征图中的像素个数,是类别的得分。
有前文指出,每一个特征图都是由某个抽象视觉模式(abstract visual pattern)所激活的。也就是说,如果,则说明该特征图对应的视觉模式被检测到,反之亦然。那么,如果偏导较大,特征图中该像素对其视觉模式中物体的出现有贡献。这意味着特征图所对应的模式需要在图像中显示得相当吻合。若一个物体的方向、视角稍有不同,或是物体中的某些部分激活了不同的特征图,将导致原本其对应的特征图不被激活。
为解决这个问题,需要将权重系数取像素级梯度的加权平均值即可。这也是GradCAM++的另一个优点。即将权重改为如下定义
其中,为类别第个特征图的像素级权重系数,其由下式计算
[1]中给出了该公式的进一步解释,在这里不做赘述。
ScoreCAM
简介
ScoreCAM[3]是2020年发表于CVPR上的改进算法。作者认为在GradCAM中,将梯度作为特征图的重要性权重有以下两点问题:
-
由于sigmoid和ReLU激活函数的使用,导致网络中不可避免的出现梯度饱和的现象。其后果是,输出对输入或内部层激活的梯度在视觉上提供的信息可能是不准确的(有噪音)。一个例子如下,图中的梯度散布在全图各处。

-
梯度不一定与权重高度正相关。对于两个有不同权重的特征图,在上述条件成立下,我们可以说:权重较大的特征图应该比权重较小的特征图对目标分数的提升更重要,或至少同等重要。但这一假设存在反例,如图所示,(2)对应的特征图权重最大,但其对目标分数的提升最少(0.003),而其他比其权重小的特征图则有更大的分数提升。

基于以上问题,ScoreCAM不使用梯度来衡量特征图的重要性,而是使用其对于目标的置信度提升(Increase of Confidence)。
方法
定义 2.1(置信度提升) 令通用函数接收向量且输出一个标量。设基线输入,原始输入中的对的贡献为将中的第个元素替换为所导致的改变量(原文中的公式可能出现错误):
其中为与相同形状的向量,,,为哈达玛积。
定义 2.2(通道级置信度提升) 令卷积神经网络模型接收向量且输出一个标量。选定中的卷积层及其对应激活图,记的第个通道为。设基线输入,对的贡献由下式定义(原文中的公式可能出现错误):
其中,为将上采样至输入图像大小的运算子,为将输入矩阵中每个元素归一化至的函数。
通过以上两个定义后,ScoreCAM的类激活映射为
其中。

基于扰动方法
IntegratedGrad
简介
本文提出了两个归因方法应该满足的公理:敏感性公理和实现不变性公理。在此基础上,作者论证了先前的若干归因方法不能同时满足所提出的两个公理,并引出了IntegratedGrad归因方法[4],其结合了Gradients和LRP[5]或DeepLift[6-7]方法。更多公理定义及细节内容,请读者参考原文。

方法
设函数为深度网络,为输入向量,为基线输入。对图像网络,基线为纯黑图像;对文本网络,基线为全嵌入向量。
考虑从基线输入的直线,integrated gradients即为累加直线上所有点的梯度。具体地,输入和基线的integrated gradients的第维由下式计算:
SmoothGrad
简介
SmoothGrad[8]提出于2017年,其关注于显著图(也称敏感图,sensitivity map)中的噪声问题。作者认为基于输入图像梯度的显著图中凸显的区域时常没有准确高亮出目标物体,因为该梯度信息存在视觉噪声。

造成上述现象的一个可能的解释是:目标分数的导数可能在很小的范围内剧烈波动。换句话说,图像中的噪声可能是由于偏导的局部变换造成的,即其并不平滑(smooth)。同时,网络中ReLU的使用将导致甚至不连续可导。
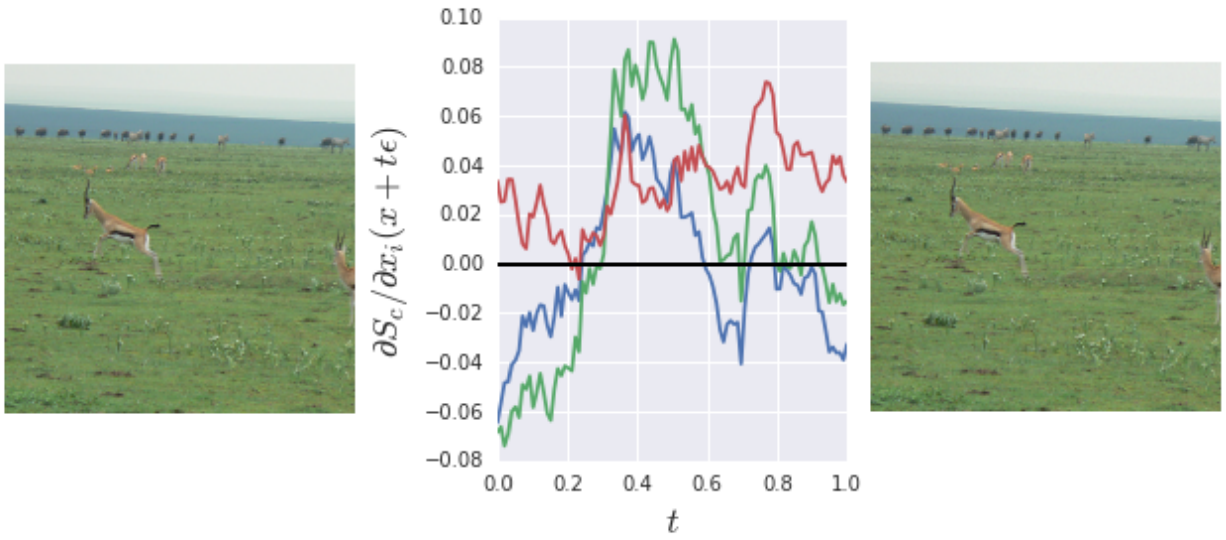
上图给出了一个例子。左右两幅图像在RGB三个通道的细微变化时,其导数也有剧烈波动。为此,作者提出使用平均化来平滑图像导数。
方法
设输入图像为,类的目标分数为,显著图的定义为:
SmoothGrad取的领域内的随机样本,并求其平均:
其中,为样本数,为以为标准差的高斯噪声。
RISE
简介
RISE[9]是一个黑盒(black-box)算法,即该算法将网络视为一个黑盒,不探究网络内部结构,如参数、特征或梯度。RISE算法的主要思想是通过对输入图像进行随机遮挡,记录遮挡图像的网络输出概率,最后根据这些概率将所有遮挡图像加权组合以得到显著图。
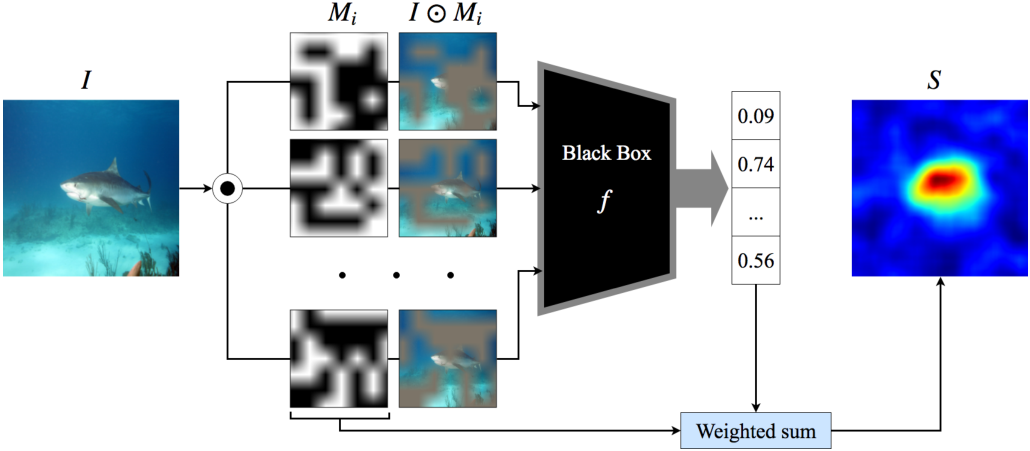
同时,[9]也提出了两个在后续论文中常用的显著图评价指标:deletion和insertion。这两个指标的具体细节于本文主题无关,请读者自行查阅。
方法
设为一个黑盒网络模型,为与输入图像相同尺寸的二进制遮挡。考虑随机变量,其中为哈达玛积,为遮挡图像的目标分数,定义像素的重要性为当未被遮挡时,即,所有可能遮盖图像的期望目标分数:
上式可重写为遮挡的求和:
其中,
将上式代入,得:
最终的矩阵形式为:
这里。显著图为随机遮挡的加权和,其中权重为随遮挡分布改变的遮挡概率得分。
在实践中,采用蒙特卡洛抽样法,抽取个遮挡,使用遮挡图像的目标分数进行加权平均再归一化,得到最终的显著图:
Extremal
简介
Extremal[10]为解决先前工作中的优化问题的不明确问题,引入极端扰动(extremal perturbations)的概念及其计算过程,将扰动分析扩展到深度神经网络的中间激活,而不是输入图像。

方法
令为输入图像,为卷积神经网络的输出激活或目标分数,extremal扰动限定于输入图像的固定比例的区域,并从足够平滑的遮挡集中选取:
其中,为惩罚系数,为惩罚项,为将向量化并以非降序排序后得到的向量,为有个紧接个的向量。
在上式定义中,遮挡仅为区域面积参数的函数。可由下式确定:
其中,为模型输出的下界(例如,为输出固定比例)。
对于的定义,设为一个像素,有
其中,为以为扰动强度的局部扰动算子(local perturbation operator),为最大扰动强度。特别地,。这里使用高斯模糊算子,。
对于平滑遮挡集的定义,此处从略。
参考文献
[1] Aditya, C., Anirban, S., Abhishek, D., & Prantik, H. Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks. arXiv 2018. arXiv preprint arXiv:1710.11063.
[2] Selvaraju R R, Cogswell M, Das A, et al. Grad-cam: Visual explanations from deep networks via gradient-based localization[C]//Proceedings of the IEEE international conference on computer vision. 2017: 618-626.
[3] Wang, H., Wang, Z., Du, M., Yang, F., Zhang, Z., Ding, S., … & Hu, X. (2020). Score-CAM: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (pp. 24-25).
[4] Sundararajan, M., Taly, A., & Yan, Q. (2017, July). Axiomatic attribution for deep networks. In International conference on machine learning (pp. 3319-3328). PMLR.
[5] Binder, A., Montavon, G., Lapuschkin, S., Müller, K. R., & Samek, W. (2016, September). Layer-wise relevance propagation for neural networks with local renormalization layers. In International Conference on Artificial Neural Networks (pp. 63-71). Springer, Cham.
[6] Shrikumar, A., Greenside, P., Shcherbina, A., & Kundaje, A. (2016). Not just a black box: Learning important features through propagating activation differences. arXiv preprint arXiv:1605.01713.
[7] Shrikumar, A., Greenside, P., & Kundaje, A. (2017, July). Learning important features through propagating activation differences. In International conference on machine learning (pp. 3145-3153). PMLR.
[8] Smilkov, D., Thorat, N., Kim, B., Viégas, F., & Wattenberg, M. (2017). Smoothgrad: removing noise by adding noise. arXiv preprint arXiv:1706.03825.
[9] Petsiuk, V., Das, A., & Saenko, K. (2018). Rise: Randomized input sampling for explanation of black-box models. arXiv preprint arXiv:1806.07421.
[10] Fong, R., Patrick, M., & Vedaldi, A. (2019). Understanding deep networks via extremal perturbations and smooth masks. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 2950-2958).
[11] Rebuffi, S. A., Fong, R., Ji, X., & Vedaldi, A. (2020). There and back again: Revisiting backpropagation saliency methods. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 8839-8848).
 微信
微信 支付宝
支付宝