

Concept-based 基于概念的解释方法
基于概念的解释方法是18年提出的新方法,其动机在于先前的方法仅使用图像的像素级特征,其通常稀疏且不易被人类理解。这是因为人类观察图像时,通常看到的是某个像素区域或图像中的某一部分,而非逐个像素的观察图像。由于其更优秀的解释表现,该方法也有更多的关注。本文将这一方法从提出到目前的研究现状(to my best knowledge)进行梳理。
CAV
Concept activation vector( CAV,概念激活向量 )[1]是基于概念的解释方法的开山之作,其框架如图1.1所示。每个概念由一个输入图像的集合定义。例如,要定义“卷发”这一概念,用户需要使用若干包含弯卷头发的发型的相关图像。
设x∈Rnx \in \mathbb{R}^{n}x∈Rn为输入图像,取神经网络模型中的第lll层,该层具有mmm个神经元,即该层对应的映射函数为fl:Rn→Rmf_{l}: \mathbb{R}^{n} \rightarrow \mathbb{R}^{m}fl:Rn→Rm。
第一步,选取可以代表一个概念的图像集合,以定义一个概念。作者认为这一策略的优点是,概念的定义不会受限于图像中已经存在的 ...

Transformer
引言
近期因导师要求,我学习机器学习的其他领域内容,于B站上观看李宏毅机器学习课程,故以记录课程笔记。
Transformer_P1_Encoder
变形金刚的英文就是Transformer,那Transformer也跟我们之后会,提到的BERT有非常强烈的关係,所以这边有一个BERT探出头来,代表说Transformer跟BERT,是很有关係的
Sequence-to-sequence (Seq2seq)
Transformer就是一个,==Sequence-to-sequence==的model,他的缩写,我们会写做==Seq2seq==,那Sequence-to-sequence的model,又是什麼呢
我们之前在讲input a sequence的,case的时候,我们说input是一个sequence,那output有几种可能
一种是input跟output的长度一样,这个是在作业二的时候做的
有一个case是output指,output一个东西,这个是在作业四的时候做的
那接来作业五的case是,我们不知道应该要output多长,由机器自己决定output的长度,即Se ...

GAN 生成对抗网络
引言
近期因导师要求,我学习机器学习的其他领域内容,于B站上观看李宏毅机器学习课程,故以记录课程笔记。
GAN_P1
Generation
Network as Generator
接下来要进入一个,新的主题 我们要讲==生成==这件事情
到目前為止大家学到的network,都是一个function,你给他一个X就可以输出一个Y
我们已经学到各式各样的,network架构,可以处理不同的X 不同的Y
我们学到输入的X
如果是一张图片的时候怎麼办
如果是一个sequence的时候怎麼办
我们也学到输出的Y
可以是一个数值
可以是一个类别
也可以是一个sequence
接下来我们要进入一个新的主题,这个新的主题是要把network,当做一个==generator==来用,我们要把network拿来做生成使用
那把network拿来,当作generator使用,他特别的地方是现在network的输入,会加上一个random的variable,会加上一个Z
这个Z,是从某一个,distribution sample出来的,所以现在network它不是只看一个固定的X得到输出,它是同 ...

Self-Attention 自注意力机制
引言
近期因导师要求,我学习机器学习的其他领域内容,于B站上观看李宏毅机器学习课程,故以记录课程笔记。
Self-attention_P1
CNN以后,我们要讲另外一个常见的Network架构,这个架构叫做Self-Attention,而这个Self-Attention
Sophisticated Input
到目前為止,我们的Network的Input都是一个向量,不管是在预测这个,YouTube观看人数的问题上啊,还是影像处理上啊,我们的输入都可以看作是一个向量,然后我们的输出,可能是一个数值,这个是Regression,可能是一个类别,这是Classification
但假设我们遇到更復杂的问题呢,假设我们说输入是多个向量,而且这个输入的向量的数目是会改变的呢
我们刚才在讲影像辨识的时候,我还特别强调我们假设输入的影像大小都是一样的,那现在假设每次我们Model输入的Sequence的数目,Sequence的长度都不一样呢,那这个时候应该要怎麼处理?
Vector Set as Input
文字处理
假设我们今天要Network的输入是一个句子,每一个句子的长度都不一样,每个句 ...

显著图的相关工作
前言
撰写本文的目的是为了总结在日常阅读论文算法的各个比较算法。通常在论文的实验部分,作者会将自己提出的算法与之前的算法进行比较。本文即为这些算法做统一梳理,从过去的论文中学习显著图这一研究领域的进展。
类激活映射方法
GradCAM++
简介
GradCAM++[1]是对经典的GradCAM[2]算法的改进。[1]的motivation是如果输入图像中同一类别的物体多次出现,GradCAM不能正确地定位图像中的各个物体,如图所示。
方法
令AkA^kAk为最尾卷积层的第kkk个特征图,GradCAM算法计算的类激活映射为
Lijc=∑wkc⋅Aijk(1.1)L^c_{ij}=\sum{w_k^c\cdot A^k_{ij}}\tag{1.1}
Lijc=∑wkc⋅Aijk(1.1)
其中,对每个特定的特征图AkA^kAk的权重由下式计算
kkc=1Z∑∑∂Yc∂Aijk(1.2)k^c_k=\frac{1}{Z}\sum\sum\frac{\partial Y^c}{\partial A^k_{ij}}\tag{1.2}
kkc=Z1∑∑∂Aijk∂Yc(1.2)
...
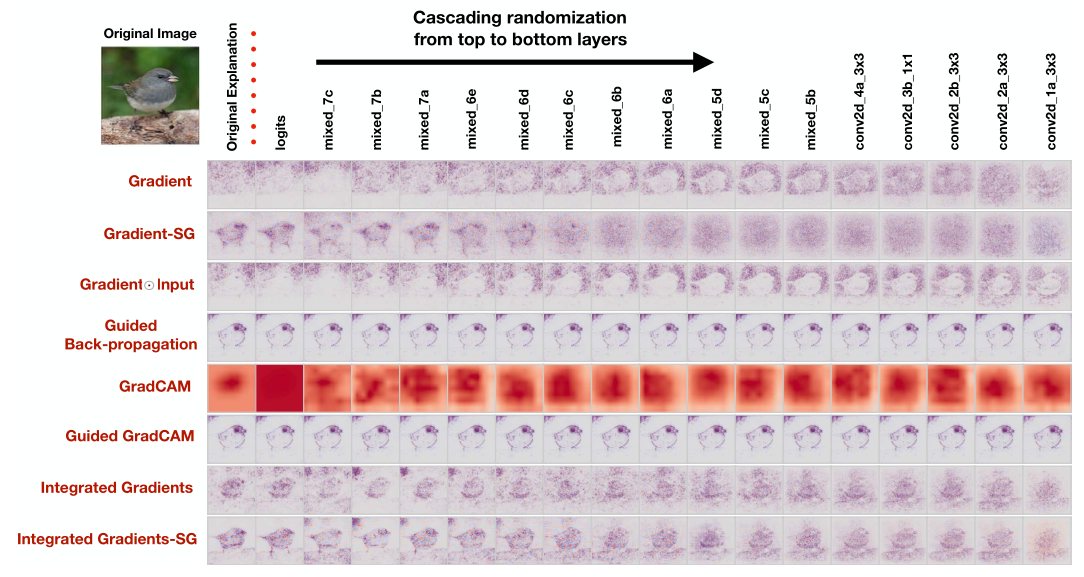
Sanity Check 完备性检验
引言
生成类显著图的可视化方法,简称显著性方法,是解释性方法里的常用方法,其突出输入图像中的相关特征,对于分类网络来说即为图像对于指定类的高度相关区域。但是,对显著性方法的评估系统还有待完善。
完备性检验(sanity check)[1]^{[1]}[1] 是用来检测这些方法充分性的评价手段,该方法简单高效且易于理解,对显著性方法的评价可谓一针见血。同时[1]中还指出,仅仅依靠人类视觉观察可视化结果的评价方式可能会导致错误,需要结合更严谨的评价指标来评估显著性方法的性能,这一点同样重要。
[1]表示,在进行大量实验后,许多显著性方法生成的显著图和图像的边缘检测器的输出非常类似。这一发现将一些算法直接“打入深渊”,至少在大多数情况下,这种算法没有真正理解模型内部的工作,由其给出的显著图对模型的解释几乎没有作用,因为这些算法就像边缘检测器一样——对网络模型没有依赖、没有解释。
两个完备性检验的测试
模型参数随机化测试
我们知道,在训练完成后,网络模型中的参数中编码了从数据集中学到的知识,其抽象能力含与其中。如果一个显著性方法输出的显著图要对解释或调试该模型有帮助,它应该对这些参数敏感。换 ...
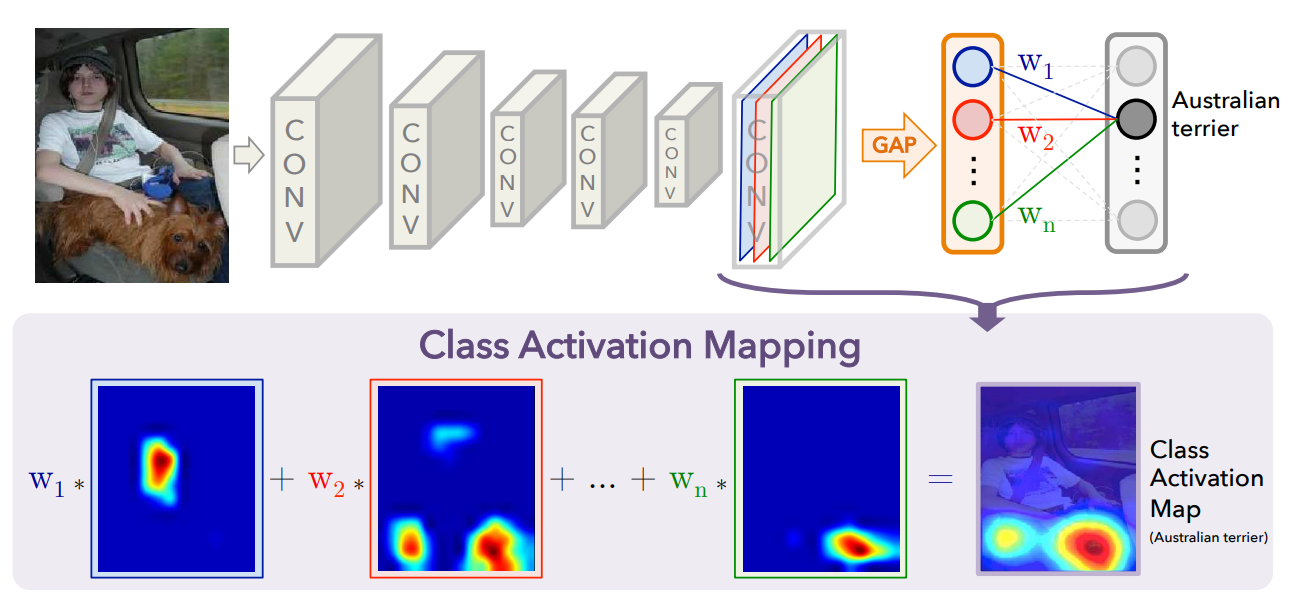
Class Activation Map(CAM) 类激活映射方法
前言
Class activation map(类激活映射,也译作类激活图)是我确定研究方向后学习的第一个可解释性中的领域。至于我为什么要选择可解释性作为自己的研究方向,需要把时间拉回到大学。在我刚接触深度学习的时候,心里就有一个自然而然的疑问:为什么神经网络可以做到以往经典的机器学习算法不能做到的事?它的精度是如此之高,以至人工智能前沿几乎没有了传统算法的痕迹。不把这个疑问弄清楚,我实在没办法说服自己搭建更深层、更精巧的神经网络模型来继续提高已有的表现。所幸这个研究方向也得到了导师的极力支持,可谓天时地利人和。
类激活映射于2016年在CVPR上被首次提出以来已5年有余,在深度学习高速发展的当下,可以称得上是”老算法“了。其建立在这样的事实之上:卷积网络中最尾卷积层的卷积核(convolutional kernel,有些论文也称为:卷积单元,convolutional unit)含有对输入图像的高度抽象。这可以解释为,在神经网络对图像进行一层一层的卷积和池化操作后,图像中的信息被凝练于各卷积层的卷积核中,最尾卷积层则含有最抽象最有用的图像信息。基于此,类激活映射分析并提取这些隐藏的信 ...